Chapter 2 Basic data structures in R
Before we jump into actual data analysis, it is desirable to first think about what are common variable types and how they are stored in R.
A variable is any characteristics, number, or quantity that can be measured or counted. A variable may also be called a data item. Age, sex, business income and expenses, country of birth, capital expenditure, class grades, eye colour and vehicle type are examples of variables. It is called a variable because the value may vary between data units in a population, and may change in value over time.(Australian Bureau of Statistics, ABS)
2.1 Types of variables: A taxonomy
2.1.1 Categorical variables: ordinal vs. norminal
Categorical variables have values that describe a ‘quality’ or ‘type’ or ‘category’.Therefore, categorical variables are qualitative variables and tend to be represented by a non-numeric value. Categorical variables should be exclusive (in one category or in another) and exhaustive (include all possible options).
Categorical variables may be further divided as being ordinal or nominal:
An ordinal variable can be logically ordered or ranked. The categories associated with ordinal variables can be ranked higher or lower than another, but do not necessarily establish a numeric difference between each category.In other words, the interval between levels of the variables are unknown. Examples of ordinal categorical variables include academic grades (i.e. A, B, C), clothing size (i.e. small, medium, large, extra large) and attitudes (i.e. strongly agree, agree, disagree, strongly disagree).
For example, when doing a survey, participants will be asked to rate. The subjective measurements of this kind are often ordinal variables. E.g. a Likert ranking scale; level of education (“< high school”, “high school”, “associate’s degree”).
We can assign numbers to different levels of an ordinal variable, but we should bear in mind that these variable are not numeric. For example, “strongly agree” and “neutral” cannot average out to an “agree”, even though you may assign 5 to “strong agree” and 3 to “neutral”.
A nominal variable is not able to be organised in a logical sequence. Examples of nominal categorical variables include sex, business type, eye colour, religion and brand.
The data collected for a categorical variable are qualitative data.
2.1.2 Numeric variables: discrete or continuous
Numeric variables have values that describe a measurable quantity as a number, like ‘how many’ or ‘how much’. Therefore, numeric variables are quantitative variables.(ABS) It is also called Interval/ratio variables and the interval between numbers is equal: the interval between 1 kg and 2 kg is the same as between 3 kg and 4 kg.
Numeric variables may be further divided as being either continuous or discrete:
A discrete variable consists of counts from a set of distinct whole values. A discrete variable cannot take the value of a fraction between one value and the next closest value. Examples of discrete variables include the number of registered cars, number of business locations, and number of children in a family, all of of which measured as whole units (i.e. 1, 2, 3 cars).(ABS)
A continuous variable can take any value between a certain set of real numbers. The value given to an observation for a continuous variable can include values as small as the instrument of measurement allows. Examples of continuous variables include height, time, age, and temperature.(ABS)
The data collected for a numeric variable are quantitative data.
The variable type will determine (1) statistical analysis; (2) the way we summarize data with statistics and plots.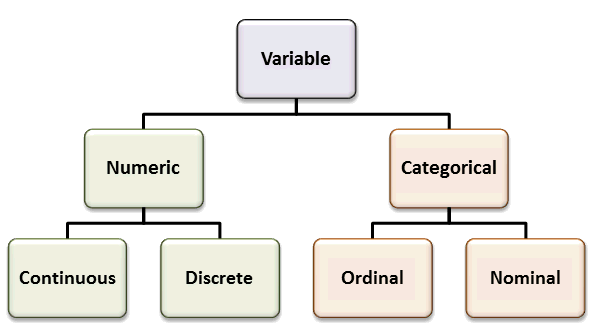
(#fig:variable_type)Taxonomy of variables
Variables can be stored in R in different data types.
Normial and ordinal variables can be stored as character or factors (with levels).
Interval data are stored as numbers either as integer or numeric (real or decimal).
If you have only one variable, you can store it in a vector. However, more often than not, you have a bunch of variables that need to be stored or imported as a matrix or data frame.
2.2 1D data structure: vectors
A vector is a sequence of data elements of the same basic type: integer, double, logical or character. All elements of a vector must be the same type.
2.2.1 Creating vectors
a = 8:17
b <- c(9, 10, 100, 38)
c = c (TRUE, FALSE, TRUE, FALSE)
c = c (T, F, T, F)
d = c ("TRUE", "FALSE", "FALSE")
# You can change the type of a vector with as.vector function.
as.vector(b, mode = "character")## [1] "9" "10" "100" "38"# When you put elements of different types in one vector, R will automatically change the type of some elements to keep the whole vector homogenous.
e = c(9,10, "ab", "cd")
f = c(10, 11, T, F)c () is a function in R.
There are some other basic functions in R that you can play with to generate vectors.
A = 9:20 + 1
B = seq (1, 10)
C = seq (1, 20, by= 2)
D = rep (5, 4)
E = rep (c(1,2,3), 4)
G = rep (c(1,2,3), each = 4)
# Now that you have a vector, you can do some Maths.
max(a)## [1] 17min(a)## [1] 8range(a)## [1] 8 17sum(a)## [1] 125mean(a)## [1] 12.5median(a)## [1] 12.5quantile(a)## 0% 25% 50% 75% 100%
## 8.00 10.25 12.50 14.75 17.00sd(a)## [1] 3.02765round(sd(a), 2)## [1] 3.032.2.2 Creating list objects
We can put vectors of different types (e.g., number, logic or character) and lengths in a list object.
list1 = list(a, b, c, d, e, f)
list1## [[1]]
## [1] 8 9 10 11 12 13 14 15 16 17
##
## [[2]]
## [1] 9 10 100 38
##
## [[3]]
## [1] TRUE FALSE TRUE FALSE
##
## [[4]]
## [1] "TRUE" "FALSE" "FALSE"
##
## [[5]]
## [1] "9" "10" "ab" "cd"
##
## [[6]]
## [1] 10 11 1 0# More often than not, we do not make list ourselves but have to deal with lists when we get outputs from stats models.2.3 2D data structures: matrice and data frames
Most of us have had some experience with the Excel spreadsheet. Data in a spreadsheet are arranged by rows and columns in a rectangular space. This is a typical 2 dimensional data structure. In R, we can have two ways of forming tabular data like a spreadsheet: the matrix and dataframe.
A matrix is a collection of data elements arranged in a two-dimensional rectangular layout in which all the elements must be of the same type (e.g., numeric or character).
Dataframe is similar to matrix in shape but only differs in that different types of data (e.g. numeric, factor, character) can co-exist in different columns. Thus, in data analysis, we use dataframes more often than matrix.
# Let's generate a dataframe from scratch.
id = seq(1, 40)
gender = rep(c("male", "female"), 5)
maths = rnorm(40, mean = 70, sd = 5)
english = rnorm(40, mean = 80, sd = 9)
music = rnorm(40, mean = 75, sd = 10)
pe = rnorm(40, mean = 86, sd = 12)
df1 = data.frame (id, gender, maths, english)Now let’s explore the data frame we just created.
str(df1)## 'data.frame': 40 obs. of 4 variables:
## $ id : int 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : Factor w/ 2 levels "female","male": 2 1 2 1 2 1 2 1 2 1 ...
## $ maths : num 75 66.8 66.2 66.8 69.7 ...
## $ english: num 70 69.7 74 90.9 88.2 ...summary(df1)## id gender maths english
## Min. : 1.00 female:20 Min. :56.35 Min. :53.08
## 1st Qu.:10.75 male :20 1st Qu.:68.46 1st Qu.:71.11
## Median :20.50 Median :69.89 Median :77.31
## Mean :20.50 Mean :70.41 Mean :77.20
## 3rd Qu.:30.25 3rd Qu.:73.45 3rd Qu.:82.20
## Max. :40.00 Max. :78.41 Max. :92.77nrow(df1)## [1] 40ncol(df1)## [1] 4attributes(df1)## $names
## [1] "id" "gender" "maths" "english"
##
## $class
## [1] "data.frame"
##
## $row.names
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
## [24] 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 402.3.1 what if I want to change column names or add variable to the df?
df2 = data.frame (id = id, gender = gender, maths = maths, english = english)
df2 = cbind(df2, pe)
colnames(df2) = c("ID", "SEX","MATHS","ENGLISH","PE")
head(df2)## ID SEX MATHS ENGLISH PE
## 1 1 male 75.01796 70.00829 81.45317
## 2 2 female 66.76527 69.69189 97.60515
## 3 3 male 66.20430 74.01194 42.85854
## 4 4 female 66.76040 90.87320 81.41710
## 5 5 male 69.72038 88.19927 68.82476
## 6 6 female 78.40910 77.38686 78.275392.3.2 Subsetting dataframes
We all know how to select part of an Excel spreadsheet by clicking and moving our mouse. In R, when we want to select part of a dataframe, we use this formula, dataframe[row, column].
There are various ways we can use this formula and believe it or not, you will love them!
# the complete dataset
df2## ID SEX MATHS ENGLISH PE
## 1 1 male 75.01796 70.00829 81.45317
## 2 2 female 66.76527 69.69189 97.60515
## 3 3 male 66.20430 74.01194 42.85854
## 4 4 female 66.76040 90.87320 81.41710
## 5 5 male 69.72038 88.19927 68.82476
## 6 6 female 78.40910 77.38686 78.27539
## 7 7 male 74.63351 72.84907 103.53668
## 8 8 female 70.20879 70.72695 75.82843
## 9 9 male 70.05682 73.92994 86.68846
## 10 10 female 72.83907 66.40915 82.75331
## 11 11 male 74.37074 78.15143 83.99379
## 12 12 female 59.28214 92.76303 83.46747
## 13 13 male 68.82831 57.60829 86.23941
## 14 14 female 67.07097 53.08478 92.80207
## 15 15 male 73.13889 81.69466 102.96310
## 16 16 female 70.93309 68.88525 88.10361
## 17 17 male 72.74304 68.15478 96.23987
## 18 18 female 72.25669 77.23339 109.31729
## 19 19 male 70.73052 71.25089 96.15179
## 20 20 female 75.22630 78.78715 67.72595
## 21 21 male 68.82996 76.23197 97.91007
## 22 22 female 76.96548 80.55444 92.41106
## 23 23 male 69.10837 81.14878 101.00206
## 24 24 female 69.59531 84.46368 84.35711
## 25 25 male 68.39574 81.23285 74.69256
## 26 26 female 75.03074 73.41064 87.77659
## 27 27 male 56.35006 88.63401 90.43346
## 28 28 female 69.08994 71.15803 86.71653
## 29 29 male 75.28302 81.68865 90.50612
## 30 30 female 69.57670 87.54575 97.37418
## 31 31 male 72.13060 83.42167 58.46628
## 32 32 female 69.68822 70.94917 73.62052
## 33 33 male 64.59905 64.67354 80.07683
## 34 34 female 69.48179 78.74199 67.77300
## 35 35 male 75.32829 81.78720 81.81599
## 36 36 female 68.47001 87.89925 99.06371
## 37 37 male 68.41000 89.30826 88.41365
## 38 38 female 68.44393 92.77329 79.07766
## 39 39 male 75.69908 75.21132 78.48825
## 40 40 female 70.69449 75.45890 87.14656df2[2:5, ] # from row 2 to row 5## ID SEX MATHS ENGLISH PE
## 2 2 female 66.76527 69.69189 97.60515
## 3 3 male 66.20430 74.01194 42.85854
## 4 4 female 66.76040 90.87320 81.41710
## 5 5 male 69.72038 88.19927 68.82476df2[ , 1:2] # select column 1 to 2## ID SEX
## 1 1 male
## 2 2 female
## 3 3 male
## 4 4 female
## 5 5 male
## 6 6 female
## 7 7 male
## 8 8 female
## 9 9 male
## 10 10 female
## 11 11 male
## 12 12 female
## 13 13 male
## 14 14 female
## 15 15 male
## 16 16 female
## 17 17 male
## 18 18 female
## 19 19 male
## 20 20 female
## 21 21 male
## 22 22 female
## 23 23 male
## 24 24 female
## 25 25 male
## 26 26 female
## 27 27 male
## 28 28 female
## 29 29 male
## 30 30 female
## 31 31 male
## 32 32 female
## 33 33 male
## 34 34 female
## 35 35 male
## 36 36 female
## 37 37 male
## 38 38 female
## 39 39 male
## 40 40 femaledf2[ , c("ENGLISH", "PE")] # select by column names## ENGLISH PE
## 1 70.00829 81.45317
## 2 69.69189 97.60515
## 3 74.01194 42.85854
## 4 90.87320 81.41710
## 5 88.19927 68.82476
## 6 77.38686 78.27539
## 7 72.84907 103.53668
## 8 70.72695 75.82843
## 9 73.92994 86.68846
## 10 66.40915 82.75331
## 11 78.15143 83.99379
## 12 92.76303 83.46747
## 13 57.60829 86.23941
## 14 53.08478 92.80207
## 15 81.69466 102.96310
## 16 68.88525 88.10361
## 17 68.15478 96.23987
## 18 77.23339 109.31729
## 19 71.25089 96.15179
## 20 78.78715 67.72595
## 21 76.23197 97.91007
## 22 80.55444 92.41106
## 23 81.14878 101.00206
## 24 84.46368 84.35711
## 25 81.23285 74.69256
## 26 73.41064 87.77659
## 27 88.63401 90.43346
## 28 71.15803 86.71653
## 29 81.68865 90.50612
## 30 87.54575 97.37418
## 31 83.42167 58.46628
## 32 70.94917 73.62052
## 33 64.67354 80.07683
## 34 78.74199 67.77300
## 35 81.78720 81.81599
## 36 87.89925 99.06371
## 37 89.30826 88.41365
## 38 92.77329 79.07766
## 39 75.21132 78.48825
## 40 75.45890 87.14656df2[c(1,2,3), ] #select the first three rows## ID SEX MATHS ENGLISH PE
## 1 1 male 75.01796 70.00829 81.45317
## 2 2 female 66.76527 69.69189 97.60515
## 3 3 male 66.20430 74.01194 42.85854df2[seq(1, 40, 2), ] #select every other rows from 1 to 40 rows ## ID SEX MATHS ENGLISH PE
## 1 1 male 75.01796 70.00829 81.45317
## 3 3 male 66.20430 74.01194 42.85854
## 5 5 male 69.72038 88.19927 68.82476
## 7 7 male 74.63351 72.84907 103.53668
## 9 9 male 70.05682 73.92994 86.68846
## 11 11 male 74.37074 78.15143 83.99379
## 13 13 male 68.82831 57.60829 86.23941
## 15 15 male 73.13889 81.69466 102.96310
## 17 17 male 72.74304 68.15478 96.23987
## 19 19 male 70.73052 71.25089 96.15179
## 21 21 male 68.82996 76.23197 97.91007
## 23 23 male 69.10837 81.14878 101.00206
## 25 25 male 68.39574 81.23285 74.69256
## 27 27 male 56.35006 88.63401 90.43346
## 29 29 male 75.28302 81.68865 90.50612
## 31 31 male 72.13060 83.42167 58.46628
## 33 33 male 64.59905 64.67354 80.07683
## 35 35 male 75.32829 81.78720 81.81599
## 37 37 male 68.41000 89.30826 88.41365
## 39 39 male 75.69908 75.21132 78.488252.4 Summary
| Dimensions | Homogenous | Heterogeneous |
|---|---|---|
| 1D | Atomic Vector | List |
| 2D | Matrix | Data frame |
| nD | Array |